
查看队列和作业信息
1.1.显示队列
命令 sinfo

队列中多节点状态不同时分行显示

显示字段包括
PARTITION 队列名称
AVAIL 队列状态
TIMELIMIT 时间限制
NODES 队列分配的节点数
STATE 节点状态
NODELIST 队列节点列表
1.1.1.队列状态值
可能的值包括: "UP", "DOWN", "DRAIN" and "INACTIVE". 默认值为 "UP"
UP
新提交的作业可能在队列上排队,并且作业可以在队列中运行。
DOWN
新提交的作业可能在队列上排队,但排队的作业可能不会被分配节点并在队列中运行。 已经在队列上运行的作业继续运行。
DRAIN
没有任何新作业可能在队列上排队(作业提交请求将被拒绝与错误消息),但已分配的队列上的作业可能被分配节点并运行。
INACTIVE
没有新作业可能在队列上排队,并且已排队的作业可能不会被分配节点并运行。
1.1.2.节点状态值
可能的状态包括:
allocated(alloc), completing(comp), down(down), drained(drain), draining(drng), fail(fail), failing(failg), future(futr), idle(idle), maint(maint), mixed(mix), perfctrs(npc), power_down(pow_dn), power_up(pow_up), reserved, and unknown(unk)。
请注意,后缀“*”标识当前未响应的节点。
idle 表示节点处于空闲状态
alloc 表示节点所有CPU都被占用,新提交的作业将排队。
drain 出现这个状态时,不影响正在运行的作业,但是不接受新的作业调度,可以使用命令sinfo –R打印节点不正常的状态产生原因

mix 节点具有分配CPU的作业,而其他的CPU状态是IDLE,新提交的作业继续运行
unk Slurm控制器刚刚启动,节点的状态尚未确定。
down 故障 节点不可用。
其他状态请参考手册man page。
1.1.3.显示队列详细信息
命令 scontrol show partition <partition name>

|
队列参数列表 |
参数解释 |
备注 |
|
AllowGroups=ALL |
此队列允许的用户组 |
|
|
AllowAccounts=ALL |
此队列允许的账号 |
|
|
AllowQos=ALL |
此队列允许的的qos |
|
|
AllocNodes=ALL |
|
待验证 |
|
Default=NO |
是否是默认队列,设置多个默认队列以最后一行的队列为默认队列 |
待验证 |
|
QoS=N/A |
|
待验证 |
|
DefaultTime=NONE |
用于未指定值的作业的运行时间限制。如果未设置,则使用MaxTime。 格式与MaxTime相同。 |
待验证 |
|
DisableRootJobs=NO |
如果设置为“YES”,则用户root将被阻止在该分区上运行任何作业。 |
待验证 |
|
ExclusiveUser=NO |
如果设置为“YES”,则节点将被专门分配给用户。 同一用户可以运行多个作业,但一次只能有一个用户处于活动状态。 使用--exclusive = user选项也可以在每个作业的基础上提供此功能。 |
待验证 |
|
GraceTime=0 |
|
待验证 |
|
Hidden=NO |
指定默认情况下是否隐藏分区及其作业。 默认情况下,隐藏的分区不会被Slurm API或命令报告。 可能的值为“是”和“否”。 默认值为“否”。 |
待验证 |
|
MaxNodes=UNLIMITED |
可以分配给任何单个作业的最大节点数。默认值为“UNLIMITED” |
待验证 |
|
MaxTime=UNLIMITED |
分配给此队列的作业的最长运行时间 |
|
|
MinNodes=1 |
|
待验证 |
|
LLN=NO |
调度作业资源到最小负载的节点上的(基于空闲CPU的数量)。 这通常只适用于具有串行作业的环境。请注意,节点权重优先于每个节点上有多少空闲资源。 |
待验证 |
|
MaxCPUsPerNode=UNLIMITED |
任何节点上可用于此分区的所有作业的最大CPU数。这对调度GPU特别有用。 |
待验证 |
|
Nodes=gpunode[1,2] |
此队列可访问的节点列表 |
|
|
PriorityJobFactor=1 |
|
待验证 |
|
PriorityTier=1 |
队列优先级 |
|
|
RootOnly=NO |
指定只有用户ID为零(即用户root)可以在此分区中分配资源。 用户root可以为任何其他用户分配资源,但请求必须由用户root启动。默认值为“NO“。 |
待验证 |
|
ReqResv=NO |
指定此分区的用户在提交作业时需要指定一个预约。此选项可用于限制可能具有较高优先级的分区或仅在预留中允许的附加资源的使用。 可能的值为“YES”和“NO”。 默认值为“NO”。 |
待验证 |
|
OverSubscribe=NO |
控制分区在每个资源上一次执行多个作业的能力, OverSubscribe的可能值为“EXCLUSIVE”,“FORCE”,“YES”和“NO”。 请注意,值为“YES”或“FORCE”可能会对具有数千个正在运行的作业的系统产生负面影响。 默认值为“否”。 |
待验证 |
|
OverTimeLimit=NONE |
|
待验证 |
|
PreemptMode=OFF |
|
待验证 |
|
State=UP |
队列状态 |
|
|
TotalCPUs=80 |
此队列总cpu数量,配置文件中节点的cpu总数 |
|
|
TotalNodes=2 |
此队列的节点数量 |
|
|
SelectTypeParameters=NONE |
分区特定的资源分配类型。此选项将替换全局SelectTypeParameters值。支持的值是CR_Core,CR_Core_Memory,CR_Socket和CR_Socket_Memory。使用需要设置系统范围的SelectTypeParameters值。 |
待验证 |
|
DefMemPerNode=UNLIMITED |
|
待验证 |
|
MaxMemPerNode=UNLIMITED |
|
待验证 |
1.1.4. 命令扩展
sinfo -d可以仅显示状态为down的节点
sinfo -V 输出slurm版本信息
|
[root@gv11 ~]# sinfo -d PARTITION AVAIL TIMELIMIT NODES STATE NODELIST debug* up infinite 0 n/a nvidia up infinite 0 n/a [root@gv11 ~]# sinfo -V slurm 17.02.6
|
1.2.作业状态
命令squeue
只显示排队和运行中的作业

显示字段有
JOBID 作业ID
PARTITION 队列名称
NAME 作业名
USER 作业所属用户
ST 作业状态
TIME 作业已运行时间
NODES 作业占用节点数
NODELIST(REASON)作业运行的结点列表(不运行作业的原因)
参数列表
|
-A, --account=account(s) |
comma separated list of accounts to view, default is all accounts |
|
-j, --job=job(s) |
comma separated list of jobs IDs to view, default is all |
|
-l, --long |
long report |
|
-n, --name=job_name(s) |
comma separated list of job names to view |
|
-o, --format=format |
format specification |
|
-p, --partition=partition(s) |
comma separated list of partitions to view, default is all partitions |
|
-u, --user=user_name(s) |
comma separated list of users to view |
1.2.1.作业详细信息
命令scontrol show job 37 或者scontrol show job 37 --detail

1.2.2. 作业状态值
常见的状态值为:PENDING, RUNNING, SUSPENDED, COMPLETING, and COMPLETED.
PENDING 排队PD
RUNNING 运行R
SUSPENDED 挂起S
COMPLETED 完成CD
COMPLETING CG
FAILED 作业运行失败F
CANCELLED 作业被取消 CA
TIMEOUT 超时 TO
其中CD,F,CA,TO都是运行结束的状态
作业步状态,仅由srun加载的任务产生作业步


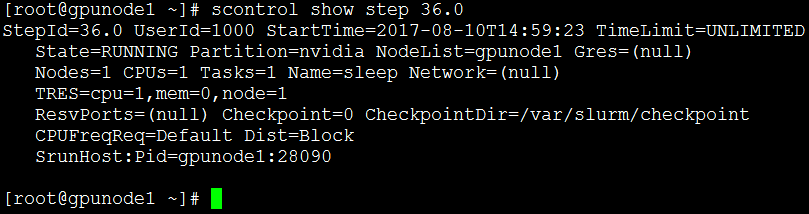
1.2.3.作业命令扩展
命令
squeue -u <user_name>查询指定用户名的作业状态

squeue –t <status_name>查询指定状态的作业

scontrol 常用参数列表
|
OPTION |
|
COMMAND |
|
|
-a or --all |
equivalent to "all" command |
cluster |
|
|
-d or --details |
equivalent to "details" command |
create |
|
|
-h or --help |
|
reconfigure |
|
|
-M or --cluster |
equivalent to "cluster" command NOTE:SlurmDBD must be up. |
show <ENTITY> [<ID>] |
display state of identified entity, default is all records. may be "aliases", "assoc_mgr" "burstBuffer", "config","daemons","federation", "frontend","hostlist","hostlistsorted", "hostnames","job","layouts", "node", "partition","reservation","slurmd", "step", or "topology"(also for BlueGene only: "block" or "submp"). |

